Abstract
Automatic 3D content creation has achieved rapid progress recently due to the availability of pre-trained, large language models and image diffusion models, forming the emerging topic of text-to-3D content creation. Existing text-to-3D methods commonly use implicit scene representations, which couple the geometry and appearance via volume rendering and are suboptimal in terms of recovering finer geometries and achieving photorealistic rendering; consequently, they are less effective for generating high-quality 3D assets. In this work, we propose a new method of Fantasia3D for high-quality text-to-3D content creation. Key to Fantasia3D is the disentangled modeling and learning of geometry and appearance. For geometry learning, we rely on a hybrid scene representation, and propose to encode surface normal extracted from the representation as the input of the image diffusion model. For appearance modeling, we introduce the spatially varying bidirectional reflectance distribution function (BRDF) into the text-to-3D task, and learn the surface material for photorealistic rendering of the generated surface. Our disentangled framework is more compatible with popular graphics engines, supporting relighting, editing, and physical simulation of the generated 3D assets. We conduct thorough experiments that show the advantages of our method over existing ones under different text-to-3D task settings.
Video
Zero-shot generation
Fantasia3D can generate high-quality 3D assets from solely text prompts.
 |
 |
 |
 |
| A delicious croissant | a metal sculpture of a lion's head, highly detailed | ||
 |
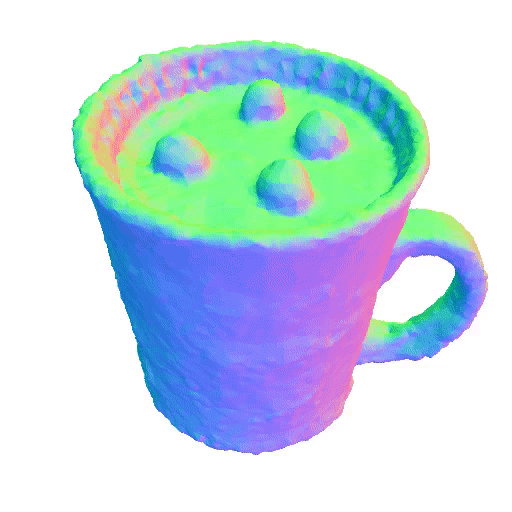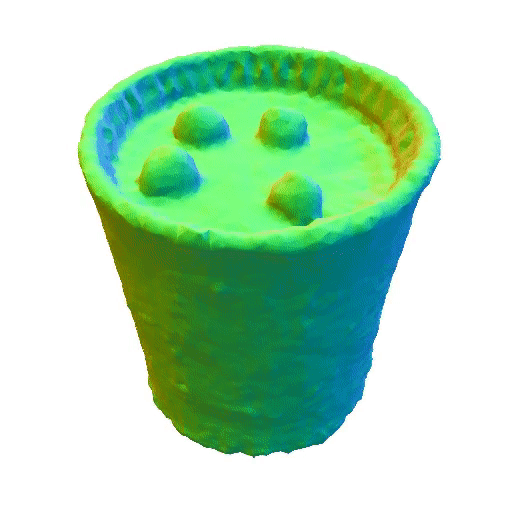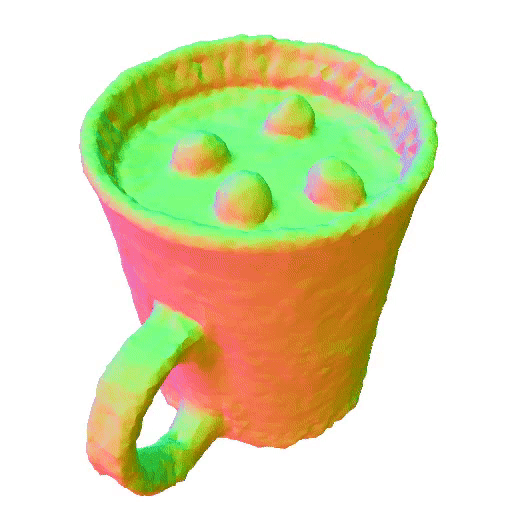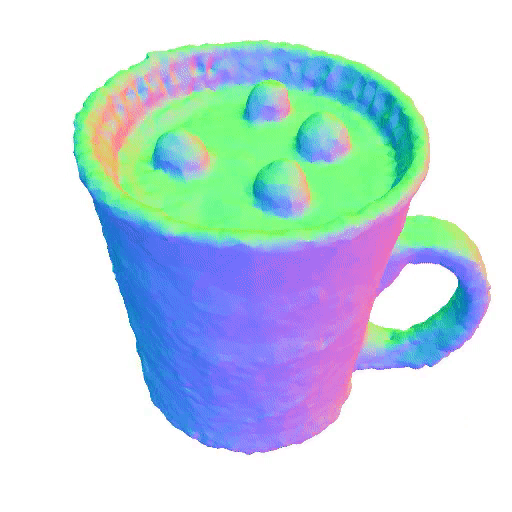 |
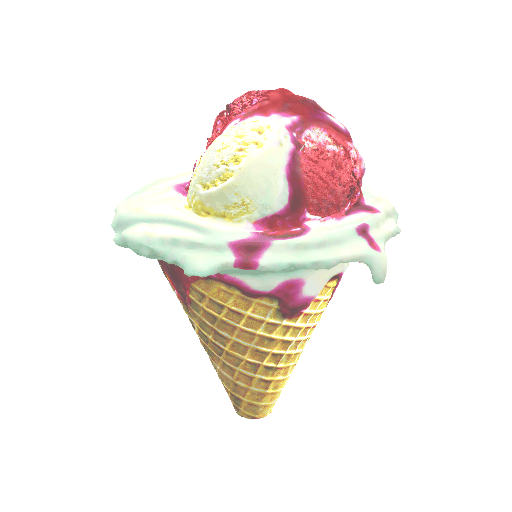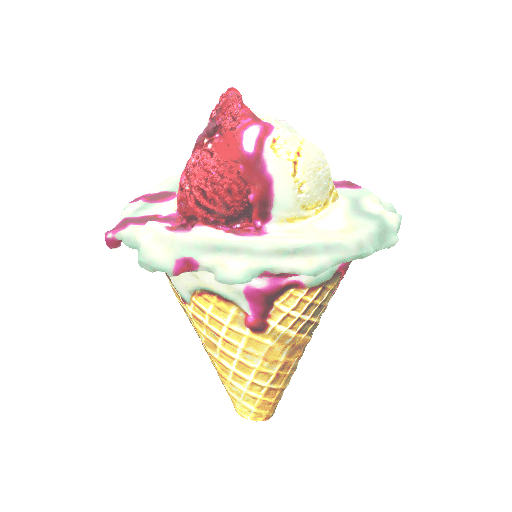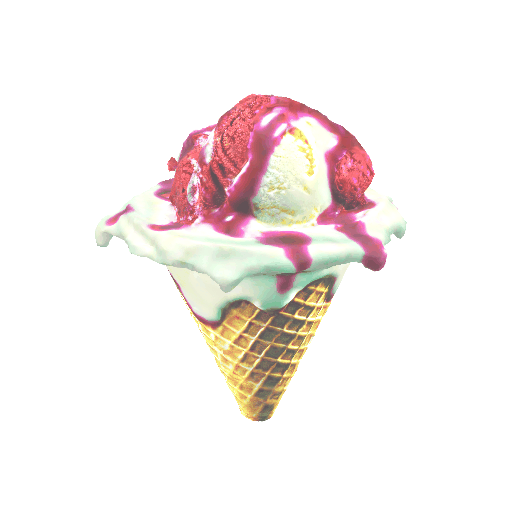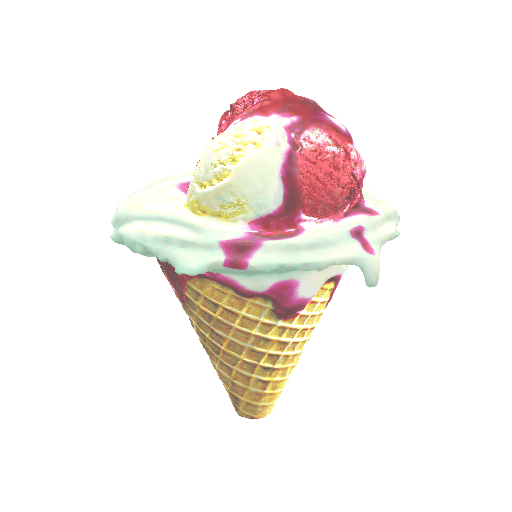 |
 |
| A mug of hot chocolate with whipped cream and marshmallows | An ice cream sundae | ||
 |
 |
 |
 |
| A highly detailed sandcastle | A fresh cinnamon roll covered in glaze, high resolution | ||
 |
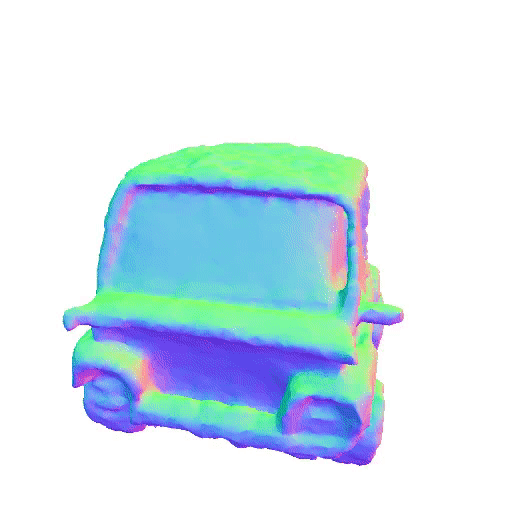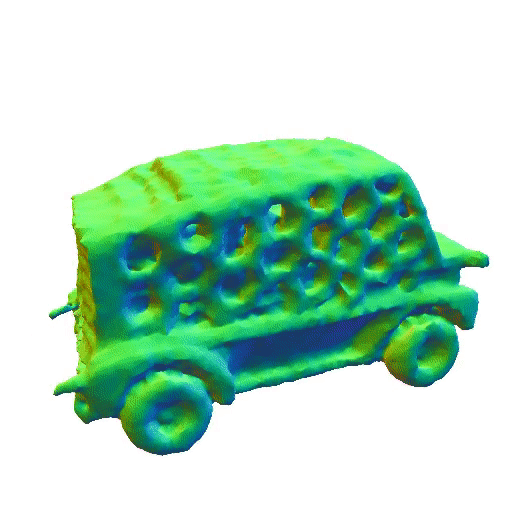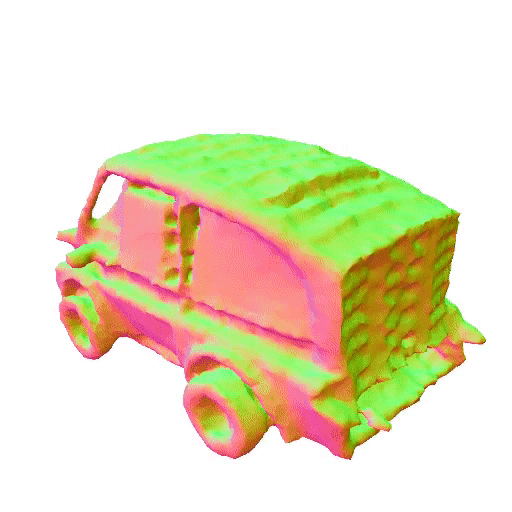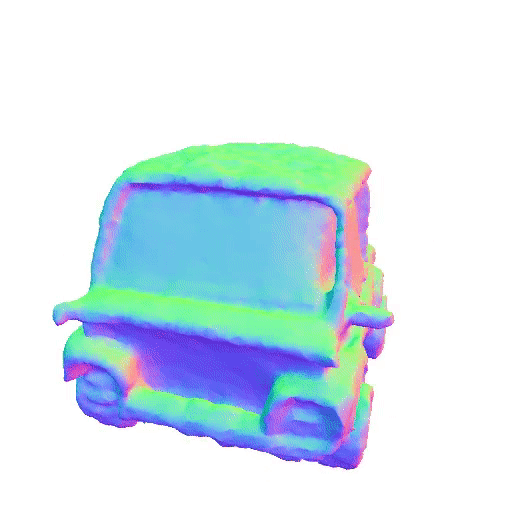 |
 |
 |
| A car made out of cheese | A vintage record player | ||
 |
 |
 |
 |
| An imperial state crown of england | A highly detailed stone bust of Theodoros Kolokotronis | ||
User-guided generation
In addition to zero-shot generation, our method is flexible to accept a customized 3D model as the initialization , thereby facilitating user-guided asset generation.

|
 |
 |
| Michelangelo style statue of dog reading news on a cellphone
|
||
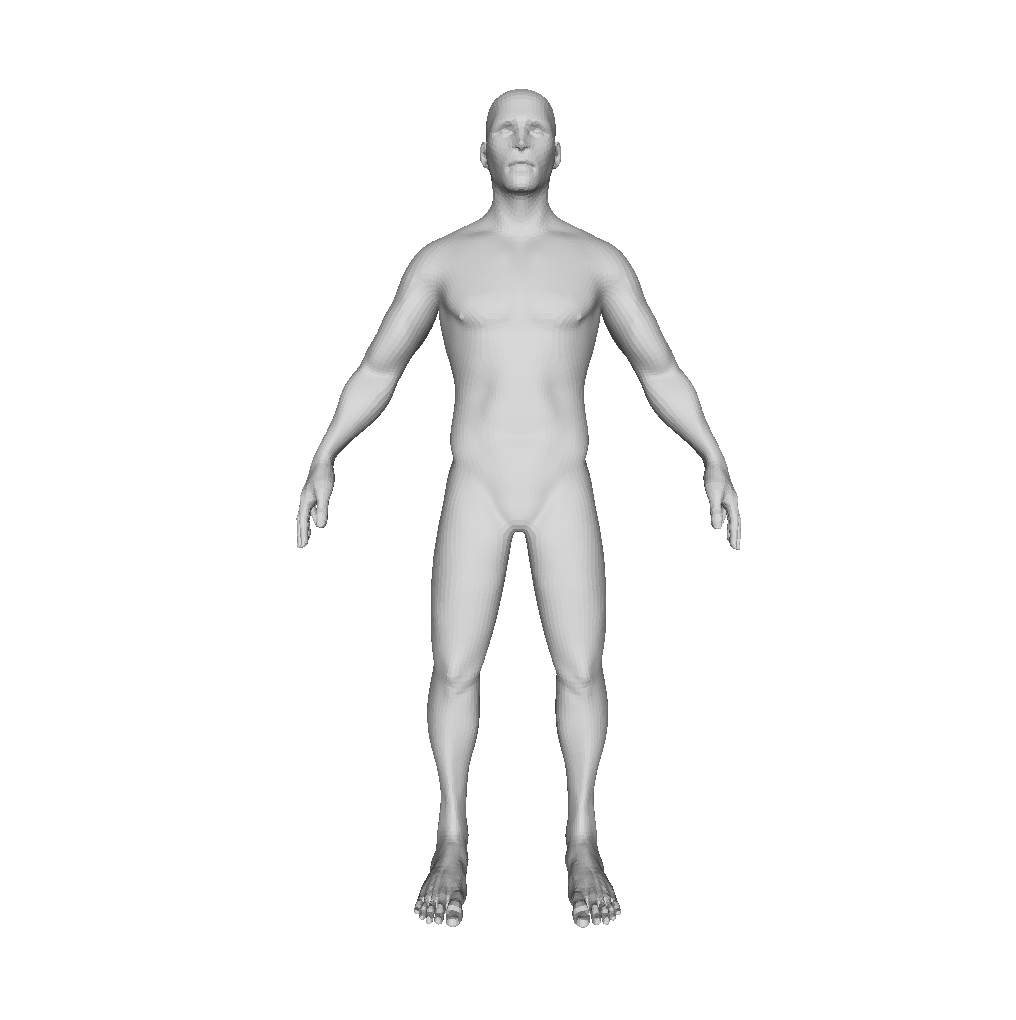
|
 |
 |
| Mobile Suit Gundam | ||
Method
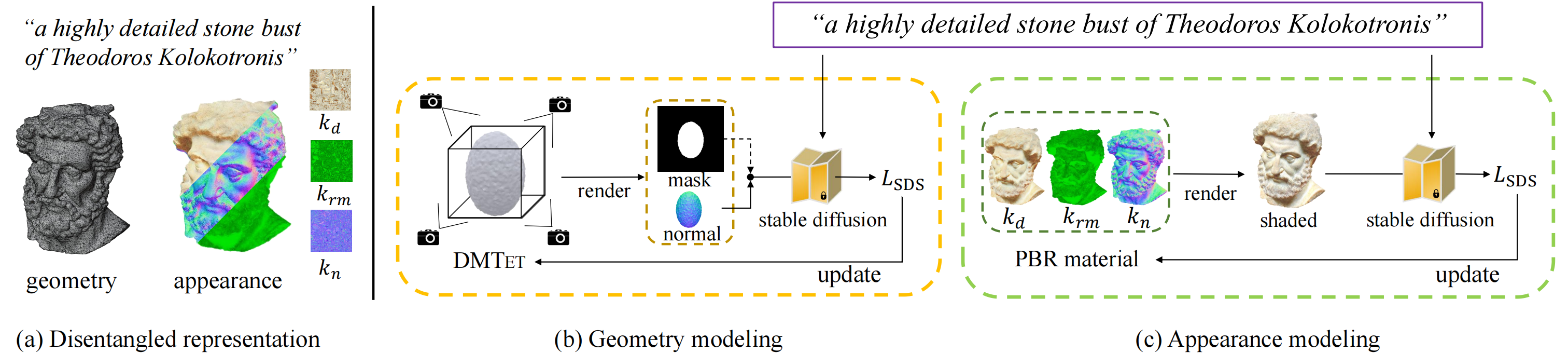
Our method can generate disentangled geometry and appearance given a text prompt (cf. figure (a)), which are produced by (b) geometry modeling and (c) appearance modeling, respectively. (b) We employ DMTET as our 3D geometry representation, which is initialized as a 3D ellipsoid here. To optimize the parameters of DMTET, we render the normal map (and the object mask in the early training phase) of the extracted mesh from DMTet as the shape encoding of stable diffusion. (c) For appearance modeling, we introduce the spatially-varying Bidirectional Reflectance Distribution Function (BRDF) modeling into text-to- 3D generation, and learn to predict three components (namely, kd, krm, and kn) of the appearance. Both geometry and appearance modeling are supervised by Score Distillation Sampling (SDS) loss.